
О звуке простыми словами42Производители Hi-Fi.
Истории и интервью114Репортажи с заводов51Репортажи с Hi-Fi выставок62"Сделай сам"42Готовые проекты Аудиомании42Пресса об Аудиомании53Видео491Фотогалерея102Интересное о звуке823Новости мира Hi-Fi2888Музыкальные и кинообзоры665Глоссарий
Stable Audio 2.0 научилась генерировать композиции длительностью до трёх минут
Модель также научилась превращать одни инструменты в другие.
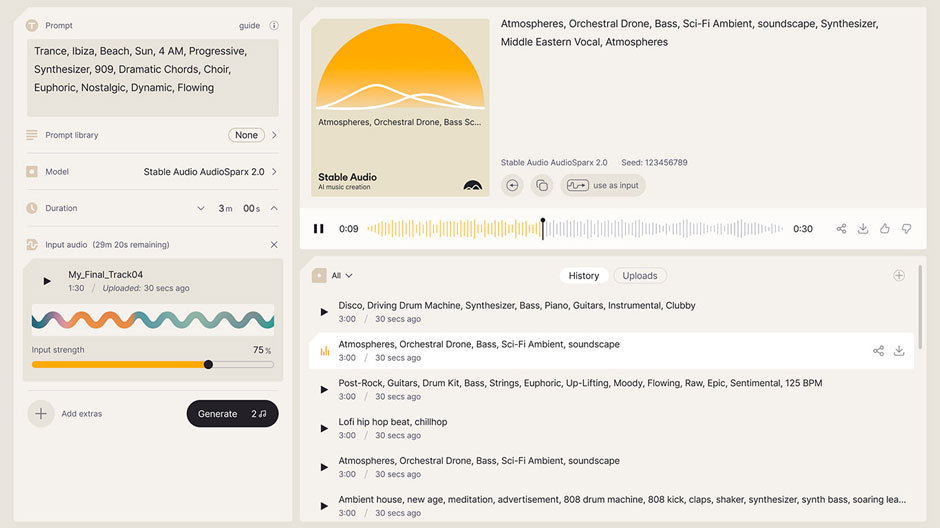
Stability AI запустила улучшенную модель Stable Audio 2.0. По словам разработчиков, теперь нейросеть генерирует «высококачественные и полностью структурированные композиции» длительностью до трёх минут.
Нейросетевая модель Stable Audio была запущена в сентябре 2023 годов. Нейросеть генерировала аудиотреки длительностью до 90 секунд наравне с мелодиями, бэк-треками, стэмами и звуковыми эффектами. За прошедшие полгода с момента запуска разработчики улучшили навыки Stable Audio, научив её генерировать структурированные композиции и преобразовывать пользовательские аудиофайлы.
Помимо увеличенной длительности генерируемой музыки и улучшенному подходу к аранжировке, одной из основных особенностей Stable Audio 2.0 стали возможности преобразования одних звуков в другие, отметили в Stability AI. В частности, модель научилась обрабатывать пользовательские аудиофайлы, превращая одни звуки в другие. В приведённых примерах использования модели разработчики показали, как нейросеть преобразовывает басовую линию синтезатора в партию бас-гитары, а ритмичный скэт-напев в полноценный бит.
По словам создателей, преобразование поможет музыкантам «трансформировать идеи в полноценные сэмплы». Несмотря на то, что функция всё ещё находится на ранних стадиях разработки, её возможности «практически безграничны», заявили в компании. В будущем нейросетевое преобразование звука может стать «чрезвычайно полезным инструментом в процессе создания музыки», особенно если оно будет внедрено в DAW или плагины.
Stability AI не комментирует возможности внедрения своей звуковой модели в цифровые рабочие станции и программы для записи музыки, хотя и отмечает, что работы в этом направлении уже ведутся. Сейчас компания сфокусирована на «улучшении текущих производственных процессов за счёт предоставления более глубоких возможностей управления и редактирования», что, по мнению разработчиков, позволит модели генерировать более интересные композиции.
Вторая версия модели получила улучшенные возможности генерации реальных звуков и эффектов. Так, например, алгоритмы более правдоподобно имитируют реальные звуки, встречающиеся повсеместно — шум леса и города, звон стекла и прочие подобные шумы.
Как и первая версия алгоритма, Stable Audio 2.0 обучалась на наборе данных из 800 000 аудиофайлов, предоставленных библиотекой AudioSparx. Авторы отмечают, что всем исполнителям, чьё творчество попало в дата-сет, было предложено отказаться от обучения модели на их музыке. Количество отказавшихся музыкантов не уточняется.
Новая версия модели уже доступна всем пользователям Stable Audio на сайте сервиса. Стоимость использования алгоритмов модели не изменилась — пользоваться платформой можно как бесплатно, так и платно. Платная подписка на использование сервиса позволяет генерировать большее количество музыки, а также расширяет возможности использования сгенерированных файлов в собственном творчестве.
Напомним, что в ноябре 2023 года, спустя два месяца после запуска модели, Stability AI покинул глава разработки Stable Audio Эд Ньютон-Рекс. Своё решение разработчик объяснил несогласием с принципами обучения искусственного интеллекта, которые кажутся ему «эксплуататорскими». По мнению Ньютон-Рекса, «компании стоимостью в миллиарды долларов обучают генеративные модели без разрешения [авторов музыки], после чего сгенерированные моделями произведения конкурируют с оригинальными работами». Stability AI не комментировала заявления разработчика, однако отметила, что модель обучалась на лицензированном наборе данных, а музыканты могли отказаться от участия в обучении алгоритмов.
Развитие алгоритмов искусственного интеллекта также вызвало серьёзную обеспокоенность в музыкальной индустрии. В частности, многие исполнители и звукозаписывающие лейблы задались вопросом, не приведёт ли бесконтрольное развитие генеративных моделей к обесцениванию творчества. Ряд известных исполнителей, таких как Билли Айлиш и Стиви Уандера, подписали открытое письмо к компаниям, занятым разработками в области языковых моделей, потребовав ограничить «хищническое использование искусственного интеллекта».
По информации издания MusicRadar, представители Stability AI не считают разрабатываемую модель потенциально опасной для музыкантов. Компания утверждает, что цель разработки состоит в том, чтобы «расширить творческий инструментарий музыкантов с помощью передовых технологий, тем самым повысив их креативность».
Подготовлено по материалам сайта "SAMESOUND", апрель 2024 г. www.samesound.ru








